
Der Google Knowledge Graph ist eine gigantische Wissensdatenbank im Web, welche Informationen strukturiert aufarbeitet, sodass kompakt-gefiltertes Wissen entsteht. Erfahre hier, welchen Nutzen der Knowledge Graph mit sich bringt.
Was ist der Knowledge Graph?
Wie gerade in der Einleitung herauskam, ist eine Definition für Wissen, dass Informationen in einen Kontext gebracht werden. Das macht der Knowledge Graph – er sucht sich Informationen und präsentiert sie in einem sinnhaften Kontext dem Suchenden. Wissenschaftlicher ausgedrückt sind mit dem Begriff Knowledge Graph sogenannte Entitäten (Knoten) gemeint, welche über Kanten in Relation zueinander gestellt sind. Diese werden noch mit Attributen bestückt und in einen thematischen Kontext (Ontologie) gebracht.
Der Aufbau und Nutzen eines Knowledge Graphs
Der Graph besteht grundsätzlich aus einer Mischung aus Knoten und Kanten. Diese bekommen einen Namen bzw. eine Bezeichnung und verschiedene Eigenschaften zugewiesen. Im Bereich der Informatik werden die Graphen benutzt, um Beziehungen zwischen Objekten zu beschreiben und zu analysieren. Facebook nutzt den Social Graph, um Verbindungen zwischen den Profilen auszuwerten. Google verwendet den Link Graph, um Verbindungen von Dokumenten und Webseiten untereinander zu analysieren und zu bewerten.
Der Google-Algorithmus versteht das Thema, nach welchem der Nutzer googelt, mithilfe vom Keyword (Schlüsselbegriff) und präsentiert dem Suchenden Zusatzinformationen. Diese Informationen, welche der Nutzer auf den ersten Blick – und ohne Klick – erhält, werden in vielfältiger Weise ausgegeben. Oberhalb oder auf der rechten Seite neben den Suchergebnissen gibt es, dank dem Google Knowledge Graph, zum Beispiel:
- Frage/Antwort-Boxen,
- Knowledge Panel,
- Knowledge Cards,
- Knowledge Karussels und
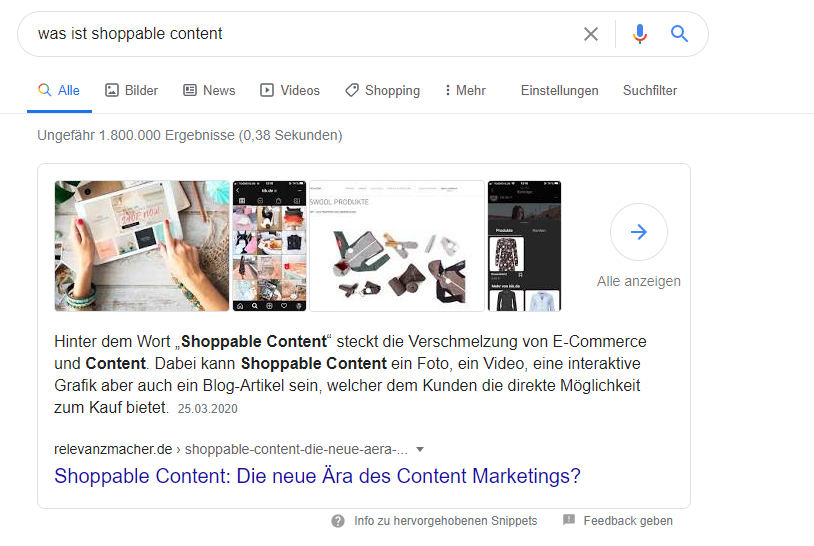
- Featured SnippetsWas ist ein Featured Snippet? Definition Ein Featured Snippet (zu Deutsch: hervorgehobenes Snippet) liefert eine prägnante und direkte Antwort auf eine Suchanfrage in den Google Suchergebnissen – ohne dabei auf eine Website klicken zu müssen. Das Snippet wird oftmals in Textform, seltener als Liste oder Tabelle und noch seltener als Video vor allen anderen organischen Suchergebnissen ausgegeben. << zurück zum.
Viele Suchanfragen sind implizit formulierte Fragen. Diese Fragen bedürfen einer Antwort. Google möchte mit den SERP-Features diese Fragen direkt beantworten. Dies ist ein Feature, was direkt oder indirekt mit dem Google Knowledge Graph verbunden ist. Um beispielsweise das Alter von Justin Bieber zu erfahren, stellen User eine Anfrage wie „Wie alt ist Justin Bieber“. Die Suche liefert prompt das Alter in einer Antwort-Box.
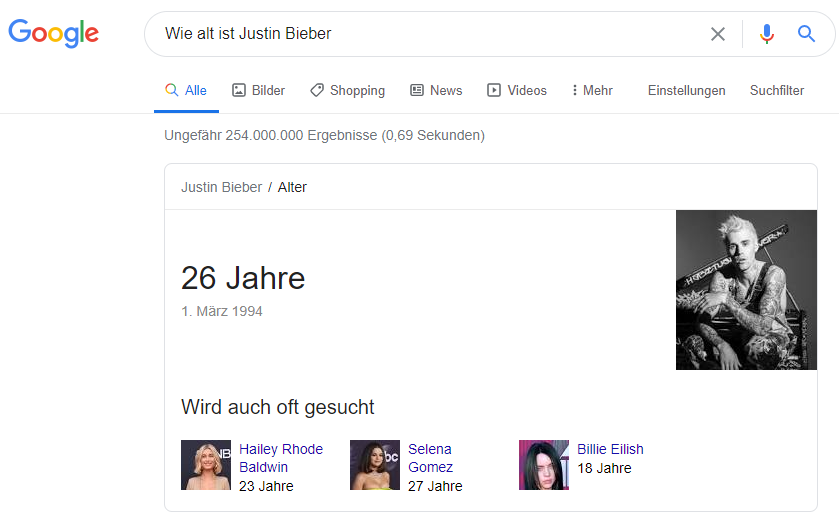
Logisch ist, dass durch diese Funktion des Knowledge Graphs der ein oder andere Klick auf die Internetseiten ausbleibt. Wikipedia berichtet von deutlich weniger Klicks auf ihrer Seite, seitdem es die Google-Antwort-Box gibt. Das Feature könnte eine Bedrohung für das E-Commerce darstellen.
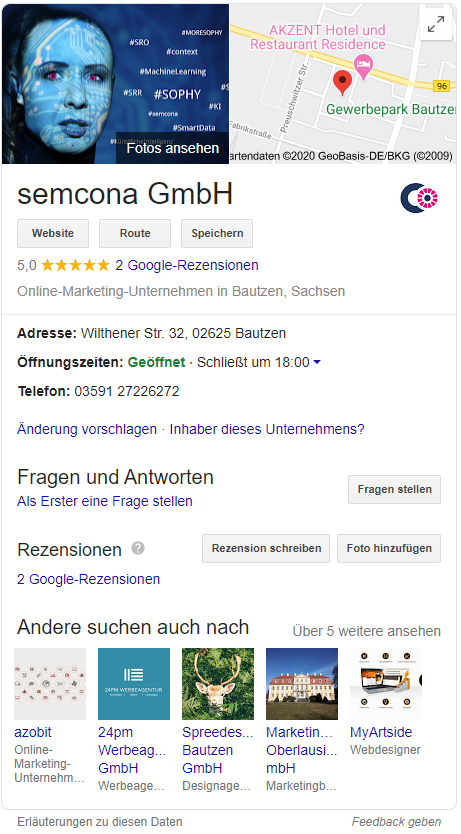
Wenn Nutzer beispielsweise ein Unternehmen oder einen Künstler suchen, werden oftmals in einem Feld rechts neben den Suchergebnissen Informationen angezeigt. Dieser Bereich nennt sich „Knowledge Panel“. Dieser hilft den Suchenden, mehr Details zum Thema zu erfahren. Zum Beispiel, wie die Kontaktaufnahme mit einem Unternehmen funktioniert oder wie dessen Öffnungszeiten sind.
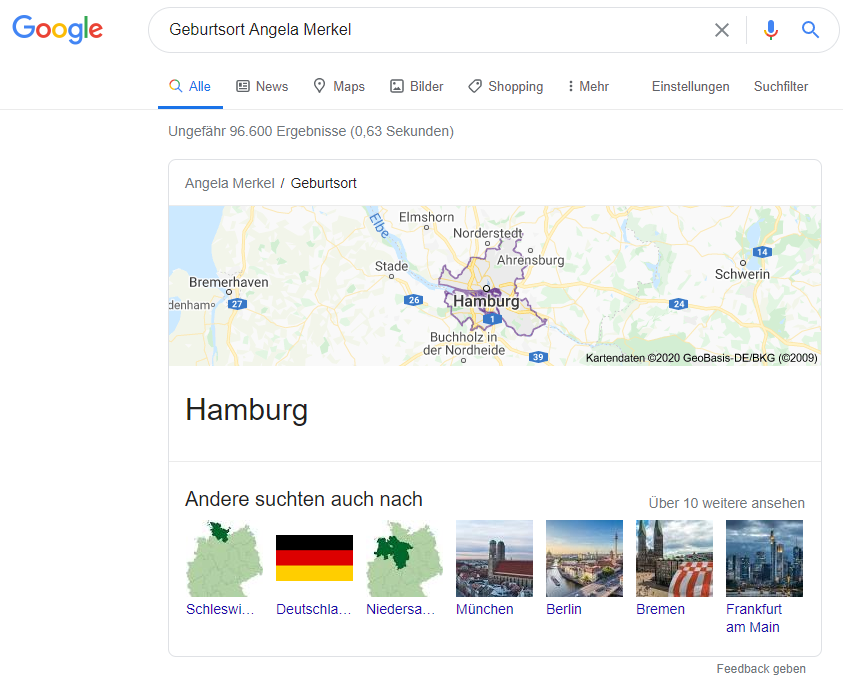
In manchen Fällen werden Knowledge Cards ausgegeben. Dies geschieht, wenn das Keyword der Suchintention rein informell ist. Informelle Suchbegriffe sind beispielsweise Alter, Geburtsort, Höhe, Größe, Beruf von Personen oder Objekten.
Das Knowledge Karussel stellt Suchergebnisse als eine Art Slider mit Bildern dar. Der Knowledge Graph liefert Ergebnisse, welche aufgrund eines sinnvollen Zusammenhangs zur Suchphrase passen. Beispielsweise können Sehenswürdigkeiten von bekannten Orten gesucht werden. Sehr wahrscheinlich werden in einem Knowledge Karussel interessante Orte angezeigt. In diesem Beispiel wurde durch die Suchphrase „Alben Justin Bieber“ die Rubrik „Alben“ ausgegeben.

Featured Snippets sind Suchergebnisse, die auf Position „Null“ auf der ersten Seite ranken. Der Text wird in einer Box über den bezahlten und den organischen Google-Ergebnissen ausgegeben. Er liefert eine kompakte und passende Antwort auf die Suchanfrage. Möchtest du erfahren, wie du es auf „Position Null“ schaffst, schau in diesen Beitrag meines Kollegen Robert Pohl: „Featured Snippets auf der Position 0 bei Google“.
Wodurch wird deine Seite im Web gefunden?
Google greift am Liebsten auf Datenbanken zu, in welche der Algorithmus bereits Vertrauen hat. Die Datenbanken und Datensets mit den Daten, welche strukturiert sind, wachsen und aktualisieren sich nur sehr langsam. Je mehr strukturierte Daten gesammelt werden, desto wahrscheinlicher ist es, dass die Suchmaschine auch unstrukturierte Daten verarbeiten kann. Strukturierte Daten funktionieren als Training für das maschinelle Lernen und die Künstliche IntelligenzWas ist Künstliche Intelligenz? Definition Künstliche Intelligenz bzw. KI (auf Englisch: Artificial Intelligence bzw. AI) ist ein Teilgebiet der Informatik. KI soll es dem Computer ermöglichen Aufgaben und Probleme zu lösen, die menschliche Intelligenz benötigen. Des Weiteren befasst sich künstliche Intelligenz mit der Automatisierung von intelligentem Verhalten, dem maschinellen Lernen (Machine Learning) und dem Deep Learning. << zurück zum Glossar im Internet der Dinge.
Google sammelt die Daten und Informationen, indem es Webseiten 24/7 crawlt. Kleine Roboter surfen durch das Internet und nehmen alles auf, was sie finden. Zu vergleichen ist dies mit den Google Street View Cars. Die Crawler sammel Daten en masse, welche alle solange nichts bedeuten, bis sie indexiert werden. Der Index ist eine Art Bibliothek, welche verwendet wird, sobald ein Nutzer einen Suchbegriff bei Google eintippt. Crawling und Indexierung sind die Grundvoraussetzungen, um bei Google gefunden zu werden. Darauf baut SEOWas ist SEO? Definition Die Suchmaschinenoptimierung (kurz: SEO, steht für Search Engine Optimization) umfasst alle Maßnahmen, die dabei helfen das Ranking einer Website in den organischen Suchergebnissen der Suchmaschinen zu verbessern und dadurch die Reichweite und den Traffic zu erhöhen. SEO ist die einzige Marketingstrategie, welche noch weiter nachhaltigen Traffic liefert, auch wenn nicht mehr in sie investiert wird. << auf.
Konsequenzen für deine Seite
Wer Google für oberflächliche Recherchen, beispielsweise für die Suche nach einem Dichter oder einem Ort, benutzt, muss die Suche nicht mehr verlassen. Die Konsequenz für stark-informationsgetriebene Seiten könnte ein hoher Traffic-Verlust sein. Wenn die Seite auch für Affiliate Marketing verwendet wird, sind niedrigere Klickraten auf Anzeigen zu erwarten. Optimierungspotenzial für SEOs besteht nun im Longtail-Bereich.
Sie müssen nun noch besser herausfinden, was der User sucht, wie er danach fragt und daraufhin die Optimierung beginnen. Wir haben die Möglichkeit auf Position „Null“ zu ranken. Sogar wenn die Seite in den organischen Ergebnissen nicht in den Top5 rankt.
Knowledge Graph – die Geschichte hinter dem Google-Tool
2012 fing Google an, mit dem Knowledge Graph zu arbeiten, welcher zuerst aus Daten von Wikipedia und Freebase gespeist wurde. Heute benutzt die Suchmaschine viele weitere Quellen, um Informationen zu sammeln. Quellen für unstrukturierte Daten sind u. a. normale Webseiten via Crawling, Suchanfragen oder unstrukturierte Datenbanken. Quellen für semistrukturierte Daten können aus Enzyklopädien oder Wikis, welche eine systematische Struktur haben, gewonnen werden.
Strukturierte Datenquellen, welche nicht mehr bearbeitet werden müssen, übernimmt die Suchmaschine beispielsweise aus Wikidata (ehemalig Freebase), Google My Business oder von lizenzierten Daten.
2013 lieferte Google mit dem Hummingbird-Ranking-Algorithmus den Anfang für den Bau einer semantischen Suchmaschine. Die Mission war Inhalte jedes Formats verstehen zu können und jeder Suchanfrage ein qualitativ hochwertiges Ergebnis zuzuordnen. Die Suchergebnisse wurden in der Suchmaschine nicht mehr hierarchisch angeordnet, sondern netzwerkartig in Form von Knowledge Graphen sortiert.
In welcher Reihenfolge die Suchmaschine die Websites angezeigt, entscheidet sie nach Rankingfaktoren. Dazu gehörten unter anderem die Keyworddichte, sowie die strategische Positionierung selbiger, als auch der Pagerank. Dieser wurde aufgrund der Menge von Links, die auf eine bestimmte leiten, berechnet. Die Keyworddichte wurde später durch komplexere Verfahren, wie TD-IDF, welches zur Beurteilung der Relevanz von Termen in Dokumenten eingesetzt wird, ausgetauscht.
Wichtiger als die Links wurden danach die Keywords für eine Suchmaschine. Durch Machine Learning wurde Hummingbird immer schlauer und orientiert sich mehr an Entitäten und Themen. Der Browser möchte Webseiten weder in Kategorien ordnen noch sie an Keywords indexieren. Google will Websites im Kontext verstehen, das heißt, dass die Kernaussage einer Webseite herauskommt. Mit dem BERT-Update vom Winter letzten Jahres optimierte Google die Relevanz zwischen Suchanfrage und Suchergebnis. Die Suchmaschine versteht die menschliche Sprache jetzt besser als je zuvor.
Google wird in den nächsten Monaten und Jahren seine Algorithmen anpassen um Nutzern die beste Search Experience zu liefern. Mithilfe des Knowledge Graph und zukünftigen Ausbaustufen wird es darauf abzielen, den User noch länger auf seiner Plattform zu behalten.



Trackbacks/Pingbacks